Building reliable agents: the agent runtime
Four runtime shapes and six reliability patterns that prevent the incidents most often seen in production.
In the previous post we put governed gateways in front of models and tools so calls are safe, observable, and swappable. That fixed the edges.
Agents still fail because the run itself is shaped and orchestrated poorly. They loop forever, blow through budget, half-apply side-effects, or get stuck waiting for a human that never shows up.
In this post we standardize:
- how a run starts (agent invocation),
- how a run lives over time (runtime shapes), and
- a small set of runtime patterns (P1–P6) that prevent the incidents most often seen in production.
Agent invocation: the contract with your runtime
Treat invocation as a standardized envelope. This decouples the trigger (HTTP, queue, schedule, button click) from the execution logic.
{
"run_id": "uuid-v4",
"intent": "triage_ticket",
"caller": { "tenant": "abc", "user": "u123" },
"budget": {
"deadline_ms": 15000,
"max_steps": 10,
"max_tools": 5,
"max_tokens": 12000,
"max_context": 8000
},
"idempotency_key": "ticket:ABC-4521:create",
"correlation_id": "parent-uuid",
"payload": { "ticket_id": "ABC-4521" }
}
Why this matters:
-
Limits at the door. Every execution is bounded by time, cost, and depth. The runtime doesn't have to guess how "big" a run is allowed to be.
-
Safe retries. The client-supplied idempotency_key lets you safely retry without double-applying work. If the client resends the same request, the runtime can look up an existing
run_idand either re-attach or return the previous result instead of starting a new run. -
Clean observability.
run_id/correlation_idglue traces and side-effects together across services, queues, and tools.
Once you have this envelope, you can feed it into different runtime shapes without changing the agent logic.
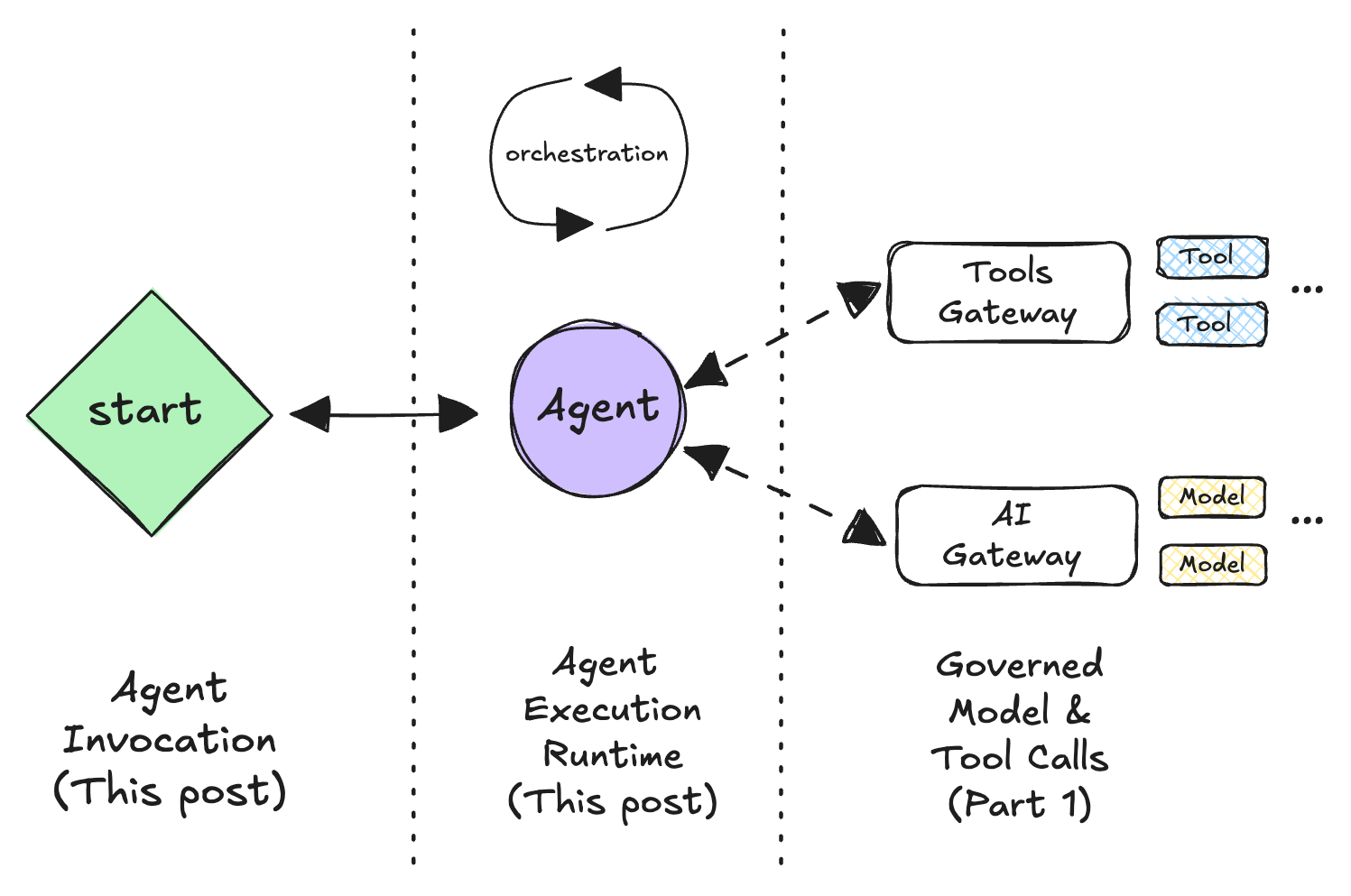
The four runtime shapes
The easiest way to reason about agent runtimes is to start with the user experience:
- Is someone waiting right now for the agent to respond?
- Or is the agent allowed to do work in the background and surface results later?
From that, four shapes emerge:
- The Service (interactive)
- The Worker (event-driven)
- The Workflow (durable)
- The Batch Job (scheduled)
You can implement all four with the same agent logic; what changes is how a run lives over time, how it's triggered, and how you keep it from breaking things.
The patterns are tagged as P1…P6 so they can be recapped later.
Shape 1: The Service (interactive)
Mental model: a person is looking at the screen (or listening on a call), and the agent is part of that live interaction.
This is the classic copilot or chat shape (plus voice). It's usually a web or mobile front-end talking to an HTTP/gRPC service that streams back tokens, tool calls, and UI events.
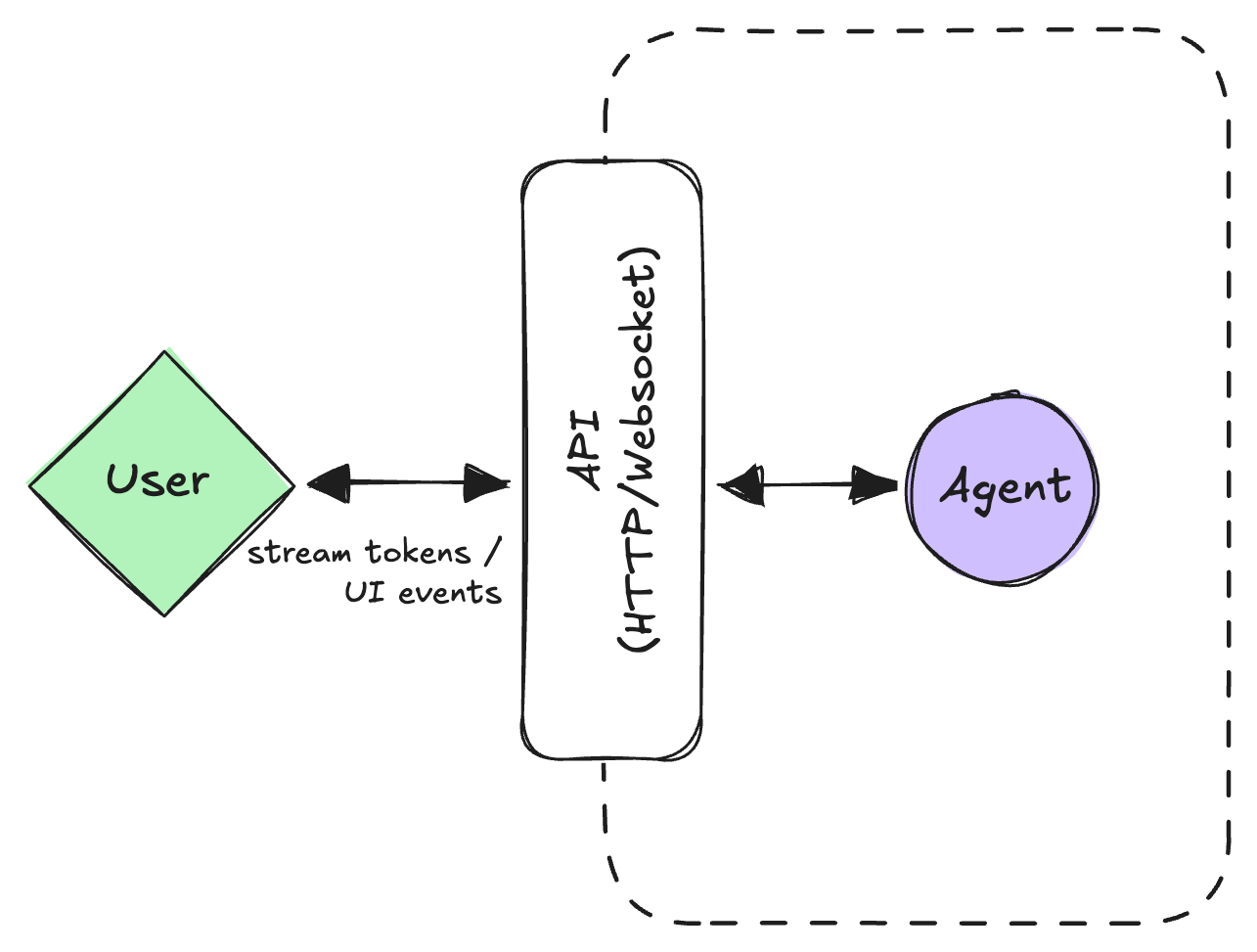
Key properties
- Low latency matters. People feel any pause over a few hundred milliseconds.
- Runs are short-lived. Think seconds, not minutes.
- State is "session-shaped." You might persist it, but you can't assume you'll run uninterrupted for 10 minutes.
Reliability patterns
-
Stream early: The fastest way to lose trust is an empty spinner. Stream something as soon as you can: "thinking…", a plan, partial answers, visible tool calls. Users forgive partial information more than silence.
-
Cancel and interrupt: You need a way for the user (or UI) to say "stop" or "change course":
cancel(run_id)→ stop work and stop burning tokens.interrupt(run_id, payload)→ treat new input as a high-priority event (e.g., barge-in for voice).
-
Per-request budgets (P2): Put a hard ceiling on what a single interactive run can spend:
deadline_msto bound latencymax_steps,max_tools,max_tokensto bound complexity and cost- as you approach those limits, degrade gracefully: switch to a cheaper/faster model, shorten context, or skip non-critical "polish" passes
-
Checkpoint on each "super-step" (P1): After a natural boundary (e.g., "plan generated", "tool X completed"), persist enough state to restart from there on reconnect or retry. You don't want to redo a multi-second tool call because someone refreshed the page.
-
Async handoff: If a run predicts it will exceed the latency budget (e.g., "I need to search 50 documents"), don't just fail. Reply with a
202 Acceptedand a link to a job ID, effectively upgrading the run from Service to Worker shape dynamically.
Common failure modes
- Long tails. A few pathological prompts that hang. Use the budget to cut them off and return a "here's what I managed so far" answer.
- Runaway loops. The model keeps re-planning instead of finishing. Step caps, traces, and P1 checkpoints make this obvious.
Examples: Customer-service agents mostly live here: a human is chatting, the agent responds in real time, and hands off or escalates when needed.
Shape 2: The Worker (event-driven)
Mental model: nobody is staring at a spinner. The agent is wired into events and does work when something happens: "ticket created", "alert fired", "invoice overdue", "email received".
The UX for this shape is usually notifications and updated records, not a chat window. In many orgs, this is where the real leverage is: agents quietly taking operational work off people's plates.
Key properties
- Triggered by events: messages, webhooks, internal change streams.
- No direct request/response: results show up later as state changes or notifications.
- Throughput and safety beat latency: better to be correct and idempotent than fast and wrong.
Reliability patterns
-
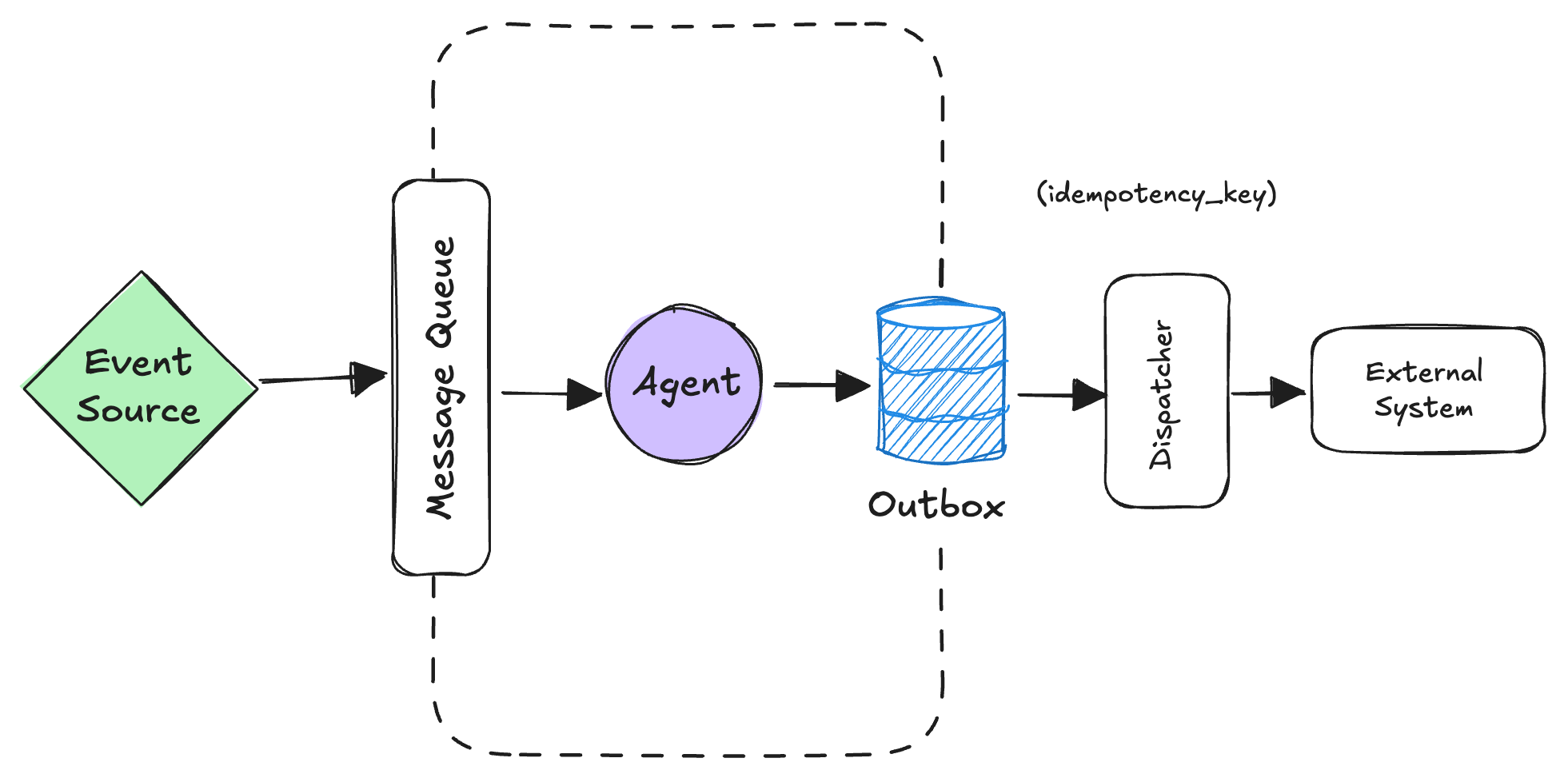
Exactly-once intent (P3): You'll get retries and duplicated events. Treat that as a fact of life:
- give each event an
idempotency_key. - on handling, record your side-effect intents in an outbox table in the same transaction as your domain update (e.g., "ticket status → RESOLVED").
- a separate dispatcher reads the outbox, calls external systems, and marks each intent done, also keyed by
idempotency_key.
Even if the message or worker retries, the external system sees the same intent at most once. This is just the transactional outbox pattern applied to agents.
- give each event an
-
Back-pressure and fairness (P6): Use queue metrics (lag, in-flight per tenant) to:
- autoscale workers when needed
- cap how many events a noisy tenant can have in flight
- move bad messages to a DLQ instead of poisoning the whole stream
-
Ordering by key where needed (P6): If you're updating the same entity (ticket, account, document), enforce ordering by a key so you don't apply updates out of order.
Common failure modes
- Treating the event handler like a web handler: long-running synchronous work, no outbox, no idempotency → duplicate side-effects and fragile flows.
- Retry storms when a downstream dependency is flaky. Circuit breakers and capped retries with jitter (P6) keep this from turning into a self-inflicted DDoS.
Examples: LangChain's ambient agents run in this shape: they subscribe to signals (email, calendar, product events), process them in the background using LangGraph, and surface work through an Agent Inbox instead of a chat.
Shape 3: The Workflow (durable)
Mental model: the agent needs to survive crashes, span multiple systems, or wait for humans. You can't just let it run in a single process.
This is where frameworks like Temporal, Airflow, or AWS Step Functions live. The agent's logic is expressed as a durable workflow graph: steps are checkpointed, resumable, and composable.
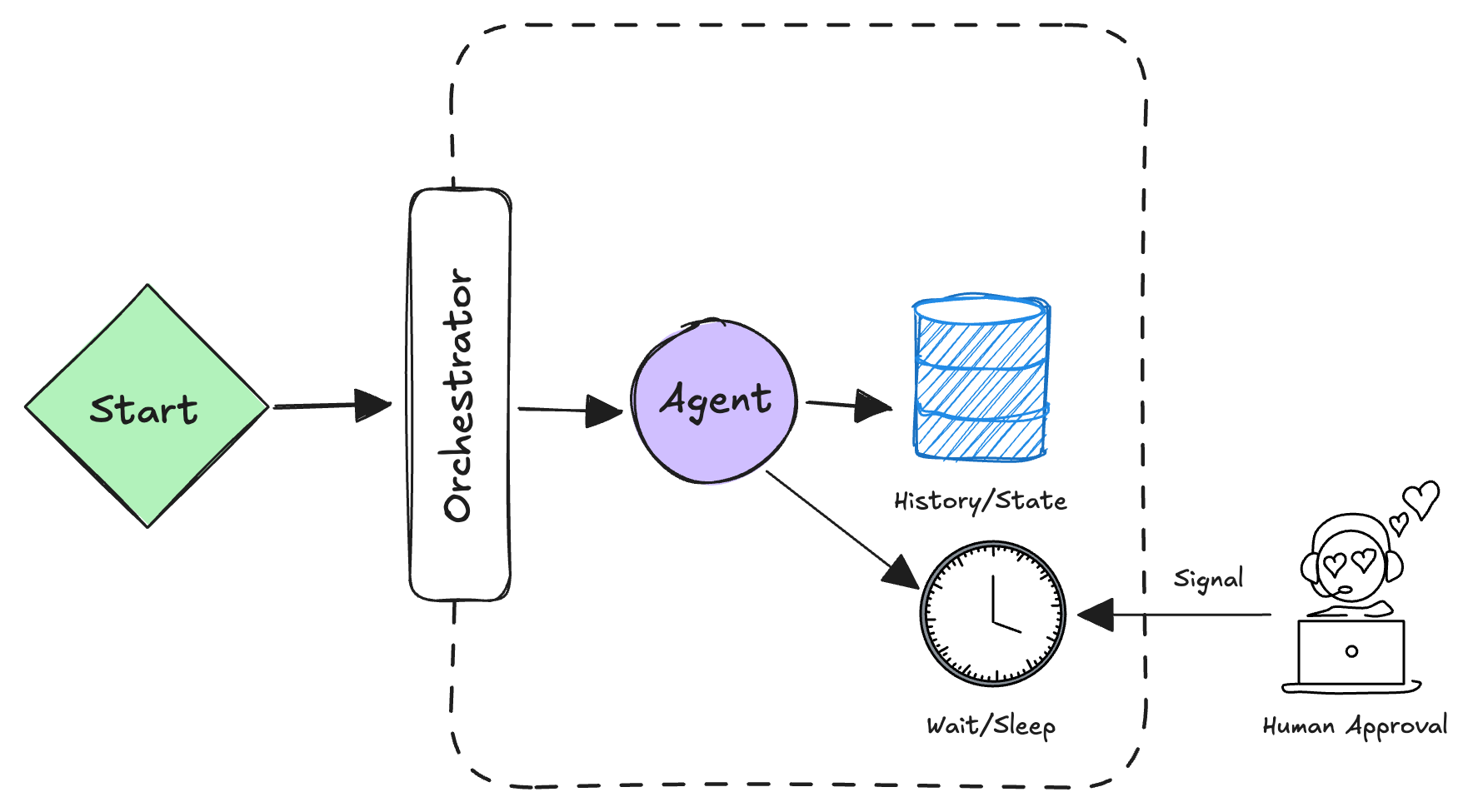
Key properties
- Long-running: minutes to hours to days.
- Distributed: spans multiple services or async jobs.
- Human approval gates: waiting for a person to review before proceeding.
- Resilient to failure: if the agent process crashes, the workflow remembers where it was.
Reliability patterns
-
Idempotent steps (P4): Every step in the workflow must be safe to retry. If you call a tool twice, it must have the same effect as calling it once. Use the
idempotency_keypattern again here. -
Explicit human gates (P5): Define where a human must approve:
require_approval(step_name, payload)→ workflow pauses, sends a notification, waits for human decision.- If approval is denied, roll back or reroute (e.g., escalate).
- If nobody responds in 24 hours, timeout and notify an admin.
-
Checkpoints and recovery (P1): The workflow framework records the state after each step. On restart, it jumps to the last completed step and resumes from there.
-
Compensation logic (P4): If a later step fails, you may need to undo earlier steps. Define compensation actions:
- created a ticket? compensation = close it.
- transferred money? compensation = refund.
Common failure modes
- Treating workflows as "just async tasks." The difference is checkpointing and state recovery. Without that, you end up retrying from the start and creating duplicate side-effects.
- Forgetting timeout handling on human gates. A workflow waits forever for an approval that nobody's monitoring. Use explicit SLAs.
Examples: a loan approval workflow: agent gathers docs, scores the applicant, flags issues, waits for human underwriter approval, then files the paperwork. If the process restarts, it picks up from where it left off.
Shape 4: The Batch Job (scheduled)
Mental model: run an agent (or many agents in parallel) over a dataset on a schedule.
This is where you precompute, bulk-label, or remediate large numbers of entities overnight.
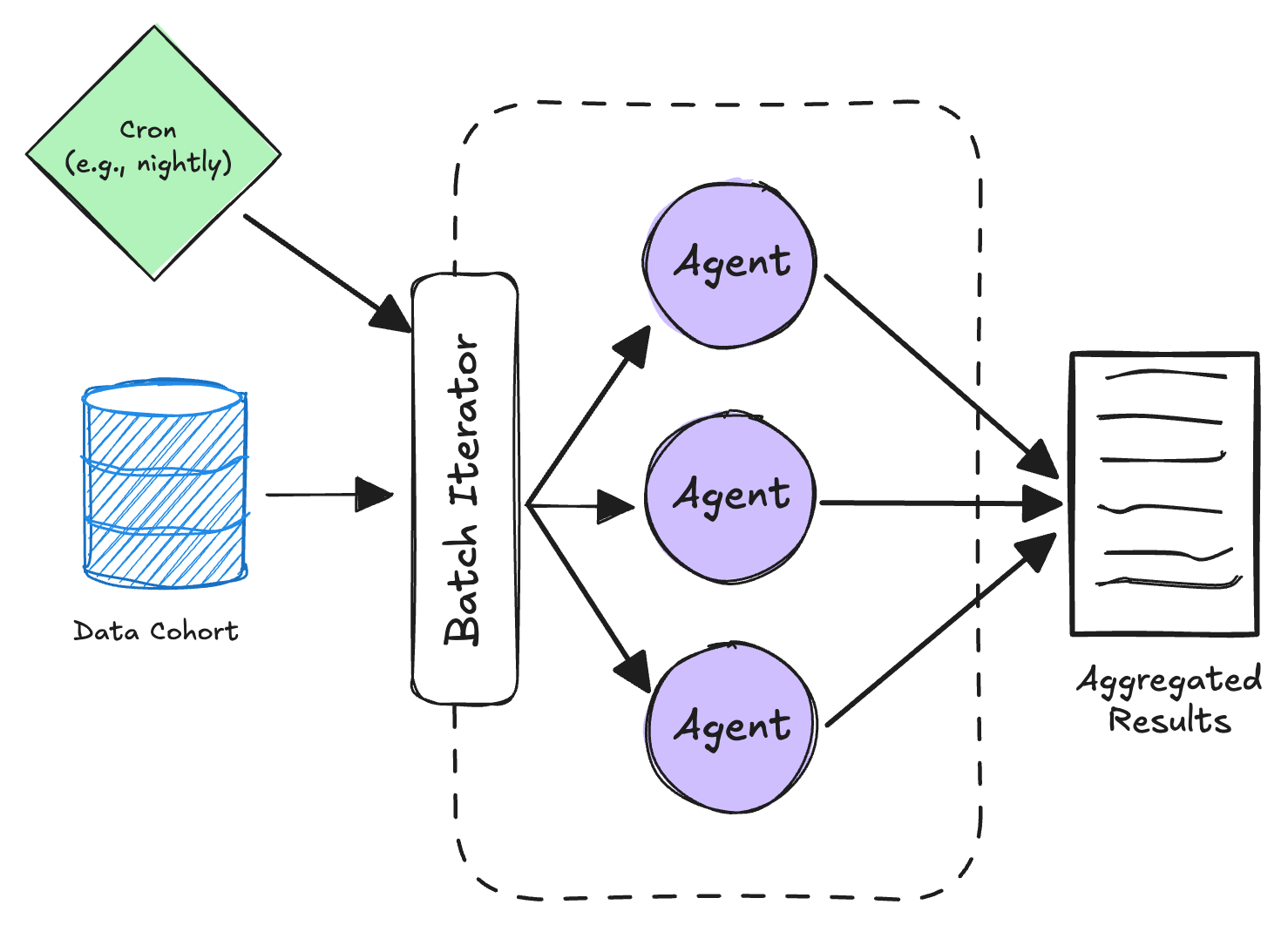
Key properties
- Throughput over latency: you have hours; optimize for correctness and cost.
- Parallelism: run 100 agents in parallel over 100 entities.
- Restartability: if a job fails halfway, restart from the last checkpoint.
Reliability patterns
-
Progress tracking (P1): Write progress to a state table so you can resume the batch from the last completed offset, not from the start.
-
Cheap "dry-run" evaluation (P6): Before committing changes, write outputs to a staging table. Have a human (or another agent) review a sample. Only apply to production if approved.
-
Per-entity budgets (P2): In a batch, you're processing 10k entities. One pathological entity shouldn't blow your entire batch budget. Cap tokens/steps per entity, and skip it if it times out or crashes.
-
Backoff and retry (P6): If the batch hits a transient error (API rate limit, downstream service blip), use exponential backoff before retrying. Don't just keep hammering.
Common failure modes
- Running a batch without a dry-run. You push 50k updates that are all wrong and have to roll back.
- No progress checkpointing. Job crashes at 95% and you restart from entity 0.
Examples: you have 50k customer accounts. Run an agent to auto-tag them by industry, write outputs to staging, review samples, and apply to the real accounts.
Cross-cutting patterns (P1–P6)
P1: Checkpoint state early and often
The problem: If a run crashes, you lose all in-flight state and must restart from the beginning.
The approach: After each major step (LLM inference, tool call, decision point), persist a checkpoint that captures the input to that step, the intermediate state, the output, and enough context to fast-forward a later worker to that point.
Tradeoff: Checkpointing adds latency and storage cost. It's worth it if your runs are longer than a few seconds or you're willing to tolerate a bit of replay.
P2: Budget enforcement (costs, time, and tokens)
The problem: An agent spins in a loop or a model hallucination causes token explosion. You don't know until the bill arrives.
The approach: Enforce hard budgets at invocation time: deadline_ms for wall-clock time, max_steps for loop iterations, max_tools for tool invocations, max_tokens for cumulative token budget, and max_context for per-call context window cap. When you approach a limit, degrade gracefully.
Tradeoff: Strict budgets can make you fail when you're "almost there." In practice, calibrate thresholds based on what you observe.
P3: Exactly-once intent and the outbox pattern
The problem: Distributed systems have retries and duplicates. If your agent executes a tool call twice, you might charge a customer twice or create duplicate records.
The approach: The transactional outbox pattern ensures that a side-effect is recorded exactly once. In a single database transaction: update your domain state and write the intended side-effects to an outbox table with an idempotency_key. A separate async process reads pending rows, idempotently calls external systems, and marks them done.
Tradeoff: Extra database round-trip and coordination. Worth it because it eliminates a whole class of bugs.
P4: Idempotency for steps and compensation for rollback
The problem: When a workflow is rolling back (because a later step failed), how do you undo earlier steps?
The approach: Make every step idempotent — calling it twice with the same inputs has the same effect as calling it once. Define compensation logic for each step that mutates state: created a record → delete it; approved a request → deny it with audit trail; sent a notification → send a follow-up correction.
Tradeoff: Compensation logic is hard to get right. You must think through all the edge cases.
P5: Explicit human approval gates
The problem: An agent makes a high-stakes decision and you can't ask for approval without stopping the entire system.
The approach: Define explicit gates where the workflow pauses and waits for human input. Set timeouts so workflows don't hang forever.
def loan_approval_workflow(app_id):
docs = agent.gather_docs(app_id)
score = agent.score_applicant(docs)
approval = require_approval(
step="underwriter_review",
payload={"app_id": app_id, "score": score},
timeout_hours=24
)
if approval.decision == "approved":
agent.file_loan(app_id)
else:
agent.notify_rejection(app_id, reason=approval.reason)
Tradeoff: Approval gates slow things down. Balance safety with throughput — use them for high-stakes decisions, skip them for low-stakes ones.
P6: Back-pressure, fair queuing, and circuit breakers
The problem: A single noisy tenant fills up your queue, or a downstream service is flaky and starts causing timeouts everywhere.
The approach: Three complementary techniques:
- Back-pressure and fair queuing: Track in-flight work per tenant, cap concurrency, return
202 Acceptedwhen overloaded. - Circuit breakers: Track failure rates per downstream service. If failures exceed a threshold, stop sending requests and fail fast. After a timeout, try again.
- Exponential backoff with jitter: Retry with increasing delays (100ms, 200ms, 400ms…) plus random jitter to prevent thundering herd. Cap max retries.
Tradeoff: These add complexity and require careful tuning. But they prevent self-inflicted DDoS and cascading failures.
Summary
| Shape | Trigger | User Experience | Key Patterns | Example |
|---|---|---|---|---|
| Service | HTTP/gRPC | Wait for response in real time | Stream, cancel, P1 checkpoint, P2 budgets | Chat, copilot |
| Worker | Event (message, webhook) | Notification + updated record | P3 outbox, idempotency, P6 fair queue | Ticket triage, email auto-responder |
| Workflow | Explicit trigger | Wait for workflow to complete | P1 checkpoint, P4 idempotency + compensation, P5 approval gates | Loan approval, document review |
| Batch | Schedule (cron, manual) | Progress dashboard, dry-run output | P1 progress tracking, P2 per-entity budgets, P6 backoff | Bulk labeling, account remediation |
These four shapes and six patterns cover most of the reliability incidents I see in production agent systems:
- Runaway loops and token explosions → P2 budgets
- Duplicate side-effects → P3 outbox + idempotency
- Lost state on restart → P1 checkpoints
- Waiting for humans that never show up → P5 approval gates with timeouts
- One bad tenant tanking everyone else → P6 fair queuing
- Flaky downstreams cascading → P6 circuit breakers
The mental model is simple: shape tells you how time and user expectations work, and patterns tell you how to keep the run from breaking.
Next up: observability and evals — how to know when a run broke and how to catch regressions before they hit users.