Building reliable agents: governed gateways
From direct calls to a governed agent platform: the gateway layer that makes demos shippable.
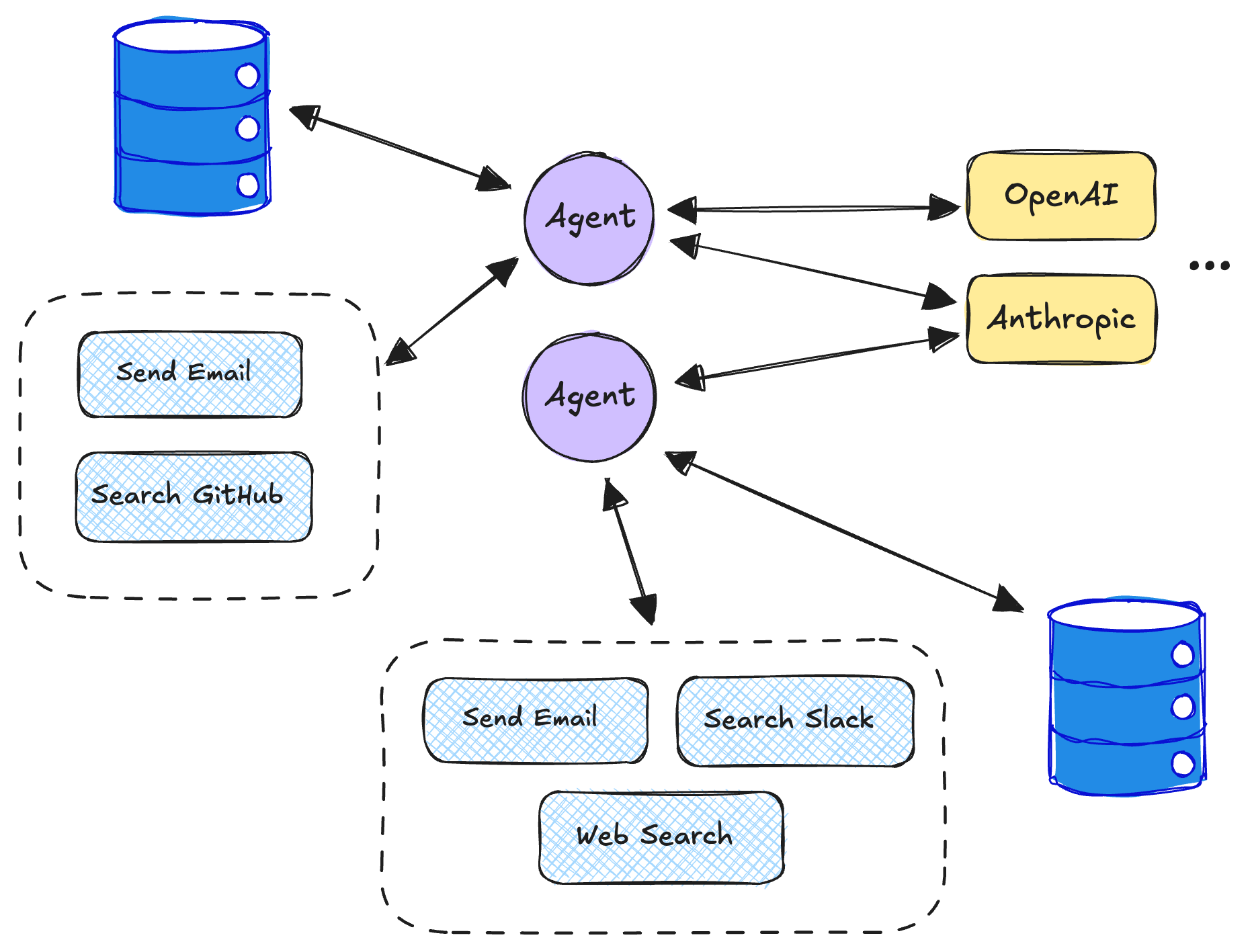
The gap between an agent demo and a production agent is mostly infrastructure. Demos assume the model is always available, the context is always right, and the agent's actions are always safe. None of that holds at scale.
This post covers eight patterns that establish governance layers around model and tool interactions — the stuff that makes agents actually shippable.
Calling models
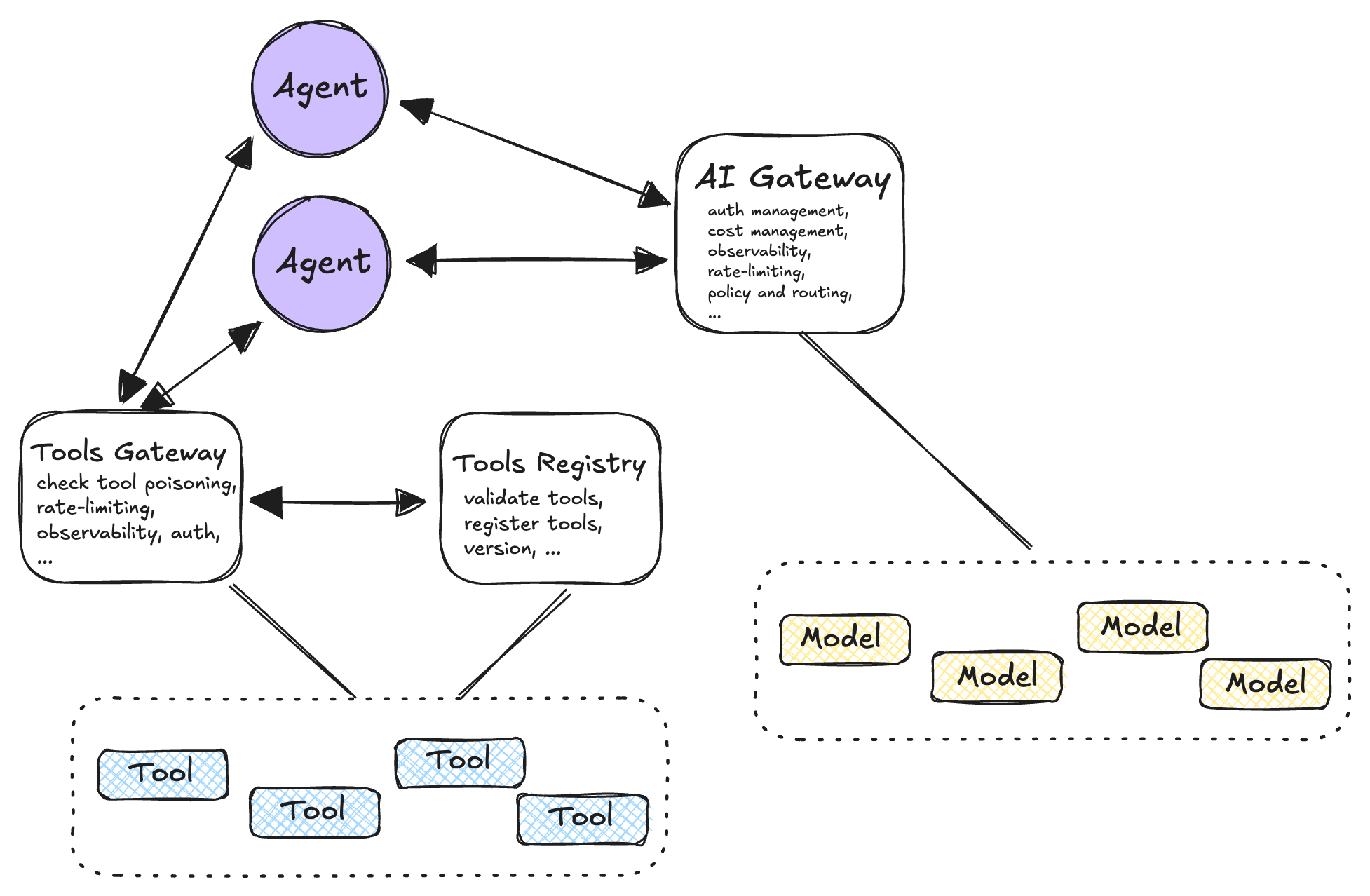
Pattern 1: AI gateway fronting all model calls
The problem: Teams call language models directly using hardcoded API keys, creating visibility gaps around costs and access control.
The approach: Route all LLM calls through a centralized gateway handling authentication, rate limiting, provider selection, and logging. This single choke point enables organizational-level controls and simplifies key rotation across deployments.
Pattern 2: Multi-provider fallback & routing
The problem: Dependence on a single provider creates service vulnerabilities.
The approach: Define model equivalence classes with ranked provider lists. The gateway automatically retries using alternative providers within latency and token budgets when primary options fail. Routing decisions can factor in latency, cost, regional requirements, or current availability metrics.
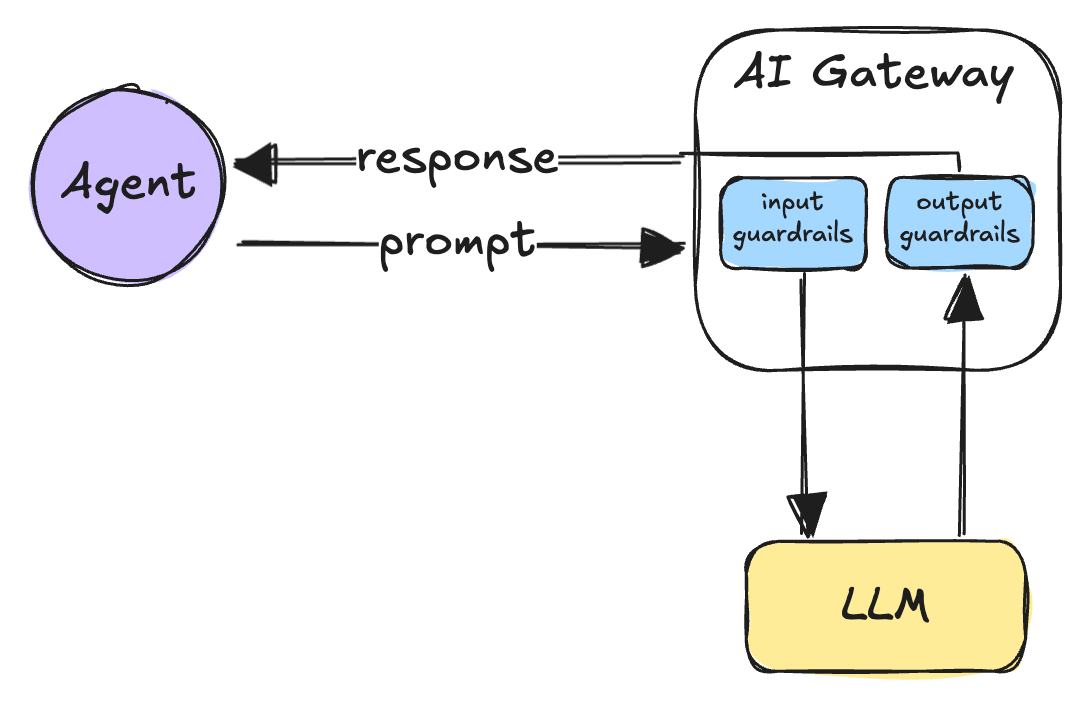
Pattern 3: Policy engine at the gateway
The problem: Agents may inadvertently send sensitive data to external models or generate harmful content.
The approach: Implement mandatory pre- and post-processing at the gateway level. Request-side filtering strips PII and blocks disallowed tools; response-side processing detects and redacts sensitive information or blocks harmful outputs. This centralizes safety enforcement without requiring individual agent implementation.
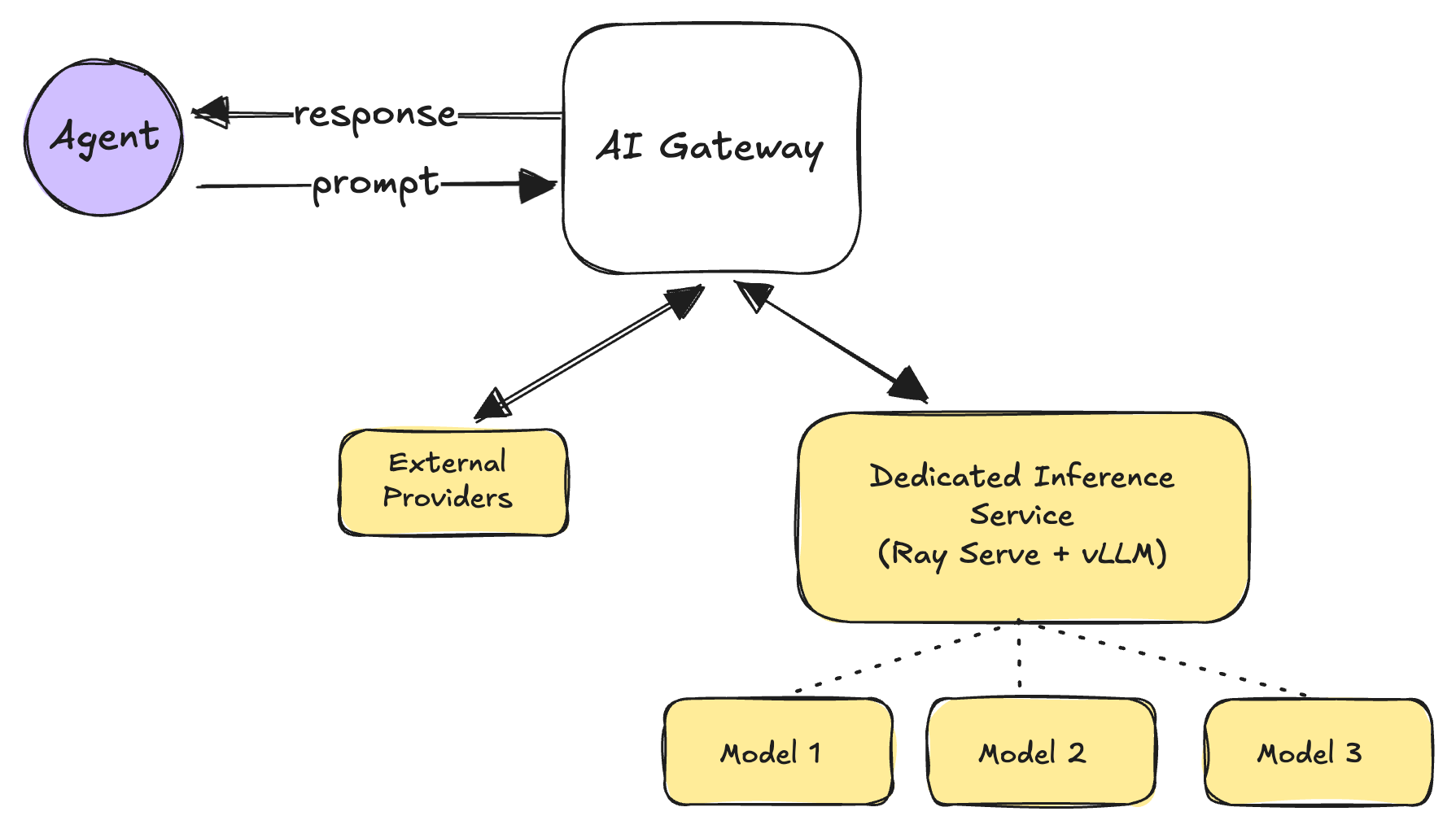
Pattern 4: Dedicated inference service with batching
The problem: Per-request model calls waste GPU resources and become cost-prohibitive at scale.
The approach: Deploy self-hosted models behind inference services using continuous batching and KV-cache reuse (e.g. vLLM, Ray Serve). This maximizes GPU throughput while maintaining consistent latency profiles aligned with user experience requirements.
Calling tools
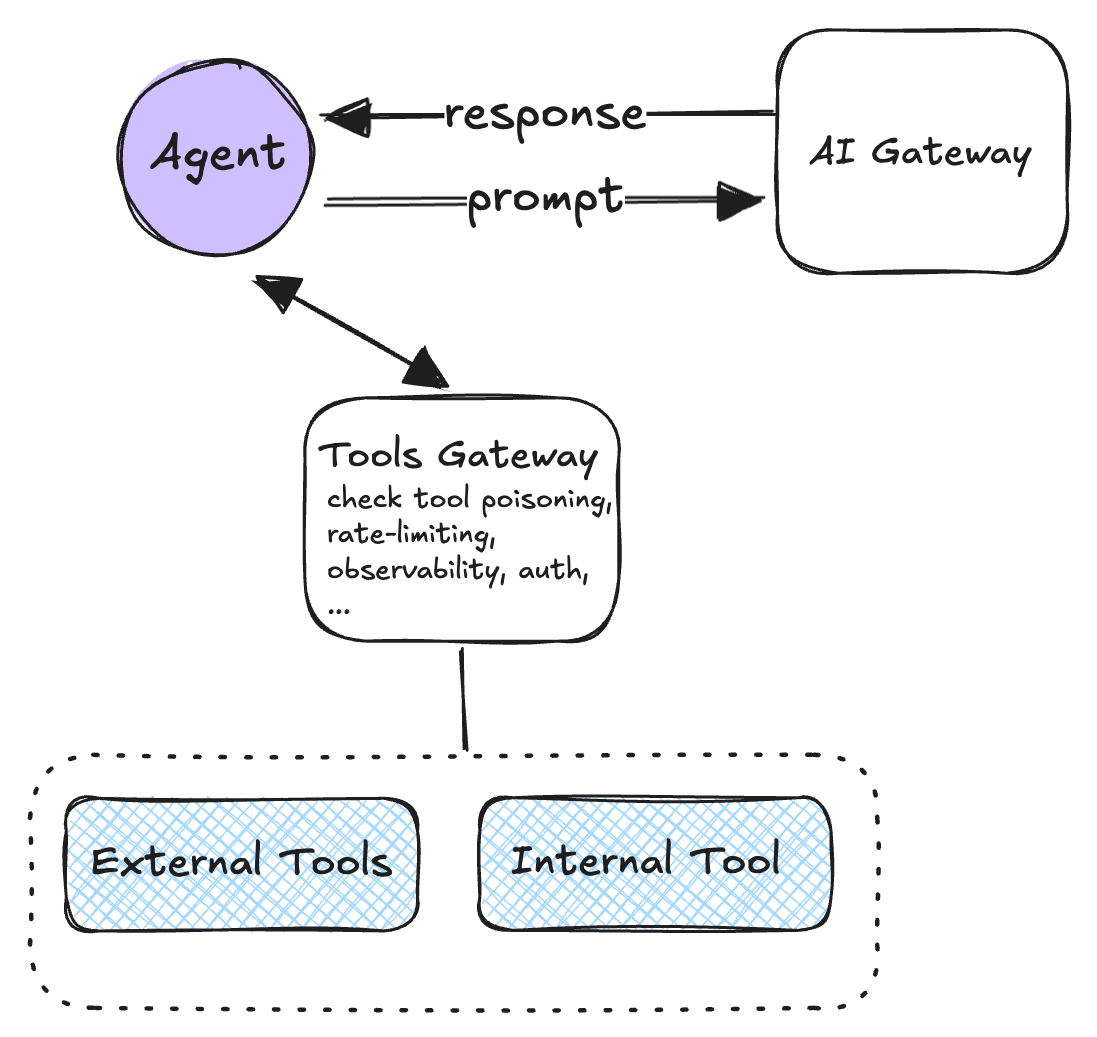
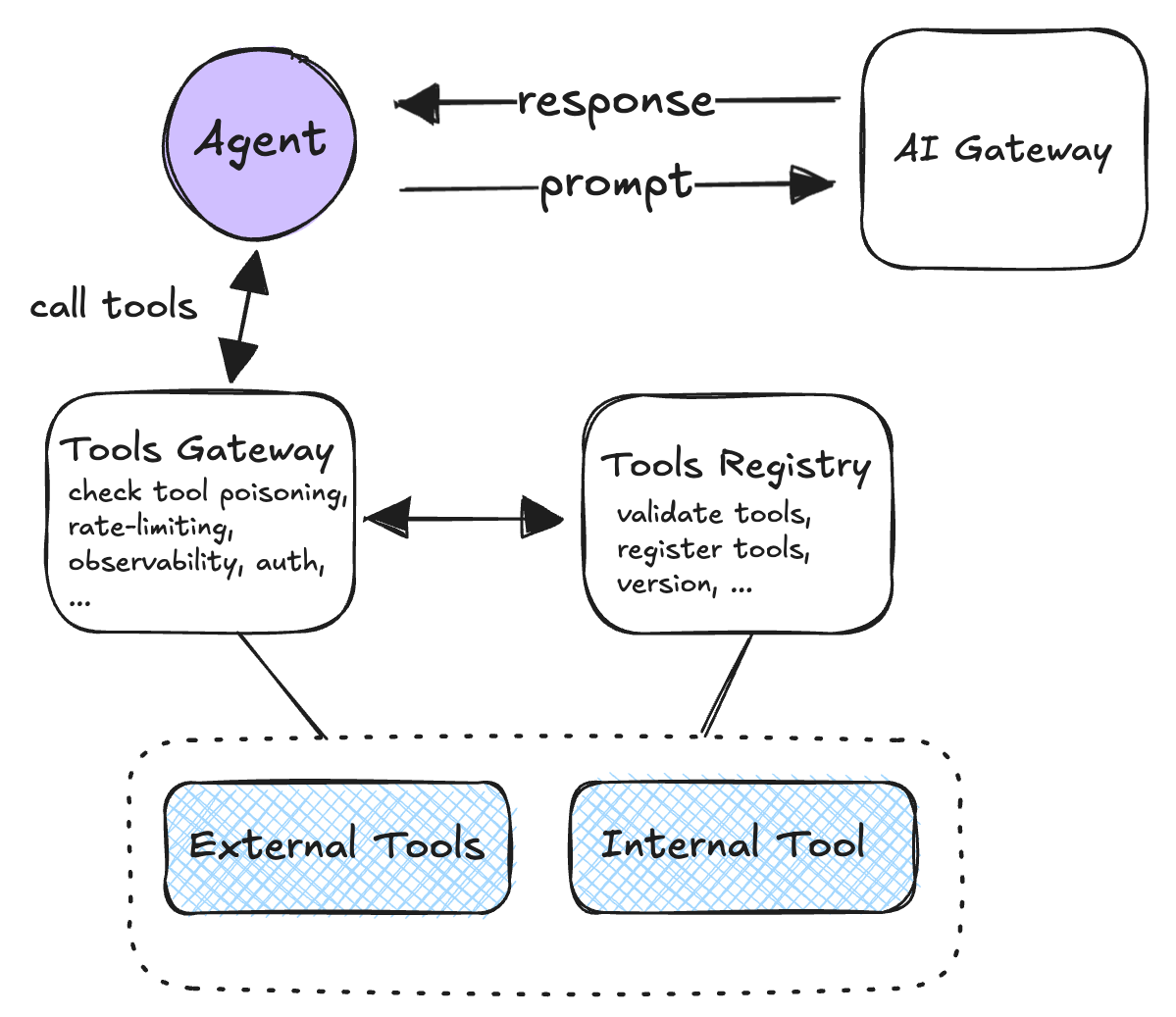
Pattern 5: Centralized tool calling via tool gateway
The problem: Direct agent-to-API connections create security vulnerabilities where compromised prompts could trigger unauthorized operations.
The approach: Route all tool invocations through a gateway that validates permissions, enforces rate limits, and maintains audit trails. The gateway handles authentication, tool registration verification, and optional protocol transcoding to backend systems.
Pattern 6: Tool registry with versioned capabilities
The problem: API schema changes break agent implementations when tools lack versioning.
The approach: Agents discover available tools dynamically from a versioned registry rather than relying on hardcoded tool references. Each tool entry includes version information, JSON schemas, and access policies, enabling safe evolution of backend APIs.
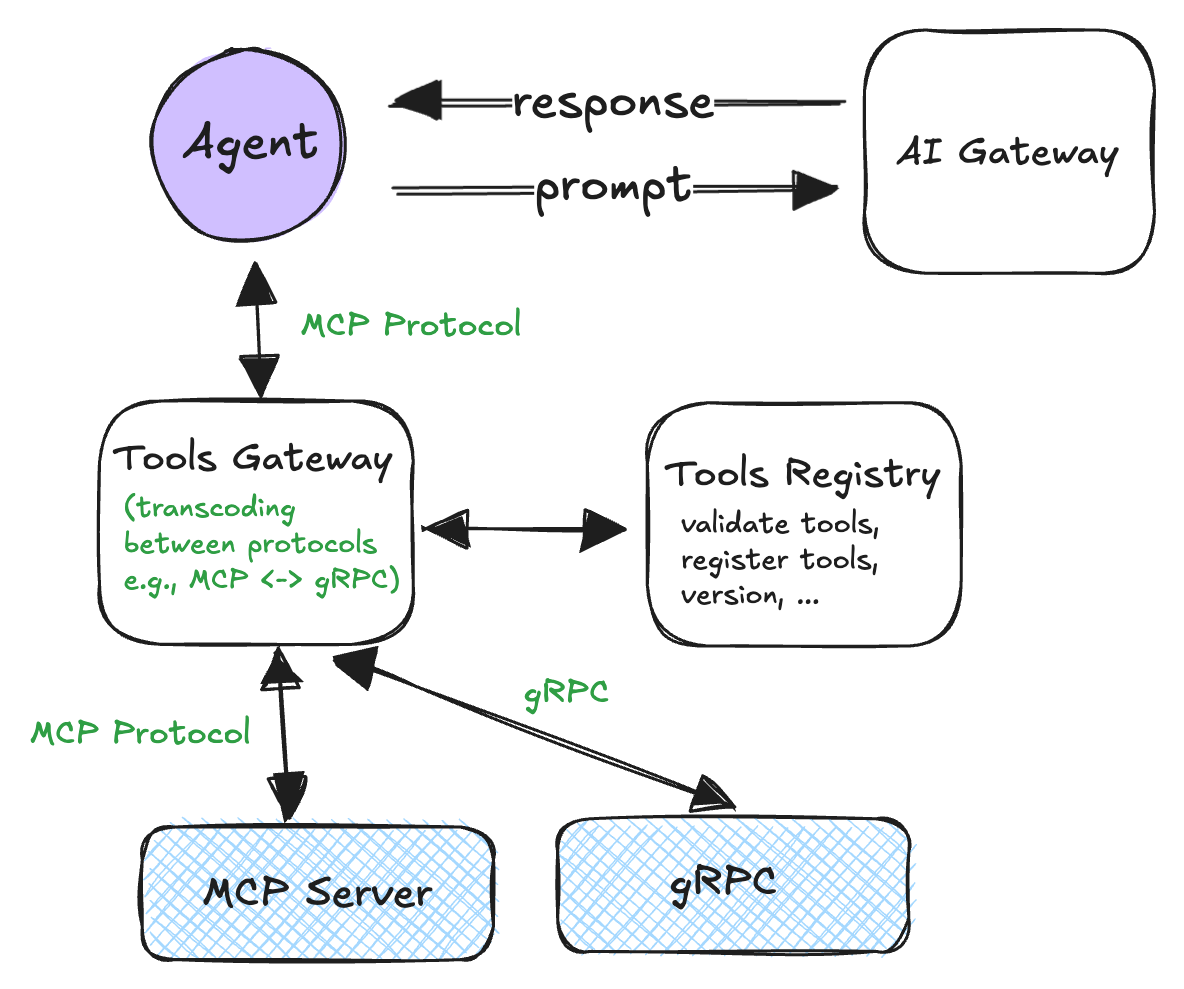
Pattern 7: Protocol transcoding for flexibility
The problem: Heterogeneous backend systems (REST, gRPC, GraphQL, proprietary RPC) force agents to understand multiple protocols.
The approach: Standardize a front-facing protocol (typically Model Context Protocol) for agent interactions while allowing the gateway to translate requests to whatever backend protocol each service requires. The registry maintains mapping information linking tool names to backend descriptors and policies.
Pattern 8: Capability-based / least-privilege access
The problem: Agents potentially access tools beyond their intended scope.
The approach: Issue short-lived, scoped capabilities for each agent run specifying exactly which tools that execution can invoke. The tool gateway enforces these boundaries, preventing prompt injection attacks from expanding agent permissions.
The full picture
Priority framework
Adopt patterns based on operational needs:
- Multiple teams/agents → Central authentication and logging (P1)
- Provider downtime → Failover mechanisms (P2)
- PII/regulated data → Input/output filtering (P3)
- Self-hosted models → Batching and cache management (P4)
- Agent-to-API calls → Authorization and auditing (P5)
- Frequently changing APIs → Versioned discovery (P6)
- Mixed backend protocols → Protocol translation (P7)
- Multi-tenant environments → Scoped permissions (P8)
Trade-offs
Each pattern introduces operational complexity alongside reliability improvements:
| Pattern | Trade-off | Mitigation |
|---|---|---|
| P1 Gateway | Additional network hop; SPOF | Multi-region active-active; circuit breakers |
| P2 Fallback | Latency variance across providers | Strict time budgets; provider allowlists |
| P3 Policy | False positives; processing overhead | Category tuning; decision caching |
| P4 Inference | Operational complexity; batch effects on UX | Separate streaming routes; autoscaling |
| P5 Tool Gateway | Additional choke point; schema drift | Health probes; scalable control plane |
| P6 Registry | Version proliferation; migration work | Deprecation windows; code generation |
| P7 Transcoding | Error semantic mismatches | Canonical error taxonomy; conformance testing |
| P8 Capabilities | Token management complexity | Short TTL (~10 min); deny-by-default |
Hybrid approaches work well — direct provider calls in low-risk development environments, gateways with policies in production. SaaS models for variable loads, inference services for predictable, cost-sensitive workloads.
These eight patterns establish the governance infrastructure that transforms agent development from chaotic, fragmented systems toward centralized, observable, and controlled platforms. Next up: runtime shapes, sandboxing, observability, evals, memory, and orchestration SDK design.